こんにちは @jedipunkz 🚀 です。
READYFOR では AWS ECS を用いてサービスを提供しています。非常に安定して運用出来ているのですが、ここ数年でプログレッシブデリバリーというデプロイ方式が登場して気になっていました。そしてこれを ECS でも実践出来ないか検討している中で PipeCD を見つけました。CNCF にジョインしているプロジェクトで AWS ECS 以外にも Kubernetes を用いることが出来る OSS になっていて、Prometheus や Datadog のメトリクスを利用することでプログレッシブデリバリーを実現しています。
PipeCD の情報はまだ少なく、特に ECS や Datadog 前提の構成を説明したドキュメントが非常に少ないので何かの役に立てばいいなと思い記事にします。
個人ブログに書いた内容との差異
個人ブログの記事 ECS + PipeCD + Datadog でプログレッシブデリバリーを実現 にも同じ内容を記しているのですが、本記事ではより考察を深堀りして個人ブログでは触れなかった課題の解決策について記そうと思っています。内容はある程度重複します。
2つの構成案
今回は2つの構成を検討しました。2つの構成の共通の特徴としては下記になります。
- piped は pipecd の API エンドポイントを指し示す
- pipecd は UI を提供
- pipecd は Filestore (S3, GCS, Minio など), Datastore (MySQL, Firestore など) を利用可
- piped は Target Group, ECS タスク定義等の操作を行うため ECS API へのアクセス権限が必要
- piped は pipeline というデプロイステージをパイプライン化する機能を有している
- piped の pipeline 上のステージで ANALYSIS という Prometheus, Datadog 等のメトリクスを解析する機能を有している
- アプリケーションレポジトリには app.pipecd.yaml を配置しターゲットグループ・タスク定義・ECS サービスを指し示す
- piped は GitHub レポジトリを参照
今回は検証目的なので
- Filestore に minio を利用
- Datastore に mysql を利用
- ANALYSIS Provider に READYFOR でも利用している Datadog Metrics を利用
という構成を検証しました。
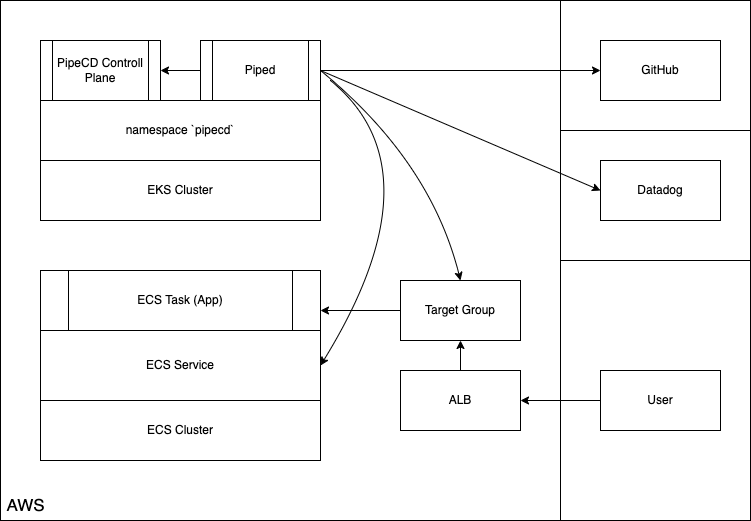
構成案1 Pipecd, Piped 共に Kubernetes (EKS) クラスタ上に起動する構成
この構成の特徴は
- piped は同 namespace 上の pipecd の kubernetes svc アドレス・ポートを指し示す
となっています。この記事では動作確認をこの構成案1. を使って行っていこうと思います。
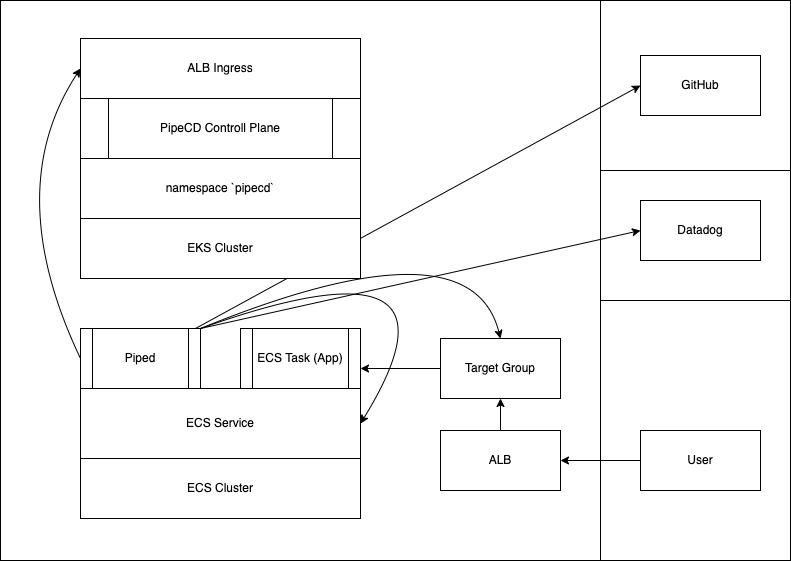
構成案2 Pipecd は Kubernetes (EKS) クラスタ上に、Piped は ECS Cluster 上に起動する構成
この構成の特徴としては
- piped が pipecd server の ALB Ingress を指し示す
となります。これは ECS 上の piped が EKS の namespace 上の piecd の API エンドポイントに接続するために Ingress が必要になるためです。今回は
- ALB Ingress Controller や Nginx Ingress等の環境整備の手間
- Piped はシングルバイナリでどこで稼働しても良い
- 同 namespace 内に起動している pipecd にアクセスできる構成1 が疎通面で都合良い
ことを考慮して、この構成は検証しませんでした。実際に PipeCD をサービス環境で運用する事を想定した場合にも、この構成を取るメリットはあまり無いように個人的には感じています。PipeCD, Piped の構成ではいずれにしても EKS (Kubernetes) を運用しなくてはならないからです。(この辺り指摘などありましたらご指導ください)
検証環境の構築手順
前提の環境
前提として下記を事前に構築・準備する必要があります。が情報量が多くなりすぎてしまうのでこの環境を整える手順は割愛させていただきます。
- ローカルマシンに helm をインストール
- EKS クラスタを構築
pipecdという名前の namespace をアサインしている Fargate Profile を用意blue,greenという ALB ターゲットグループ・リスナーを用意
アプリケーションレポジトリの用意
下記のディレクトリ構成でレポジトリを作成する
. ├── app.pipecd.yaml ├── servicedef.yaml └── taskdef.yaml
タスク定義ファイル
taskdef.yaml として下記の内容を保存します。
family: pipecd-nginx-sample executionRoleArn: arn:aws:iam::********:role/ecs-taskexecution-iamrole containerDefinitions: - command: null cpu: 100 image: public.ecr.aws/nginx/nginx:1.23-alpine memory: 100 mountPoints: [] name: web portMappings: - containerPort: 80 compatibilities: - FARGATE requiresCompatibilities: - FARGATE networkMode: awsvpc memory: 512 cpu: 256 pidMode: "" volumes: []
ECS サービスファイル
servicedef.yaml として下記の内容を保存します。
cluster: arn:aws:ecs:ap-northeast-1:********:cluster/ecs-cluster serviceName: pipecd-nginx-sample desiredCount: 2 deploymentConfiguration: maximumPercent: 200 minimumHealthyPercent: 0 schedulingStrategy: REPLICA deploymentController: type: EXTERNAL enableECSManagedTags: true propagateTags: SERVICE launchType: FARGATE networkConfiguration: awsvpcConfiguration: assignPublicIp: ENABLED securityGroups: - sg-******** subnets: - subnet-******** - subnet-********
Piped が参照するコンフィギュレーションファイル
app.pipecd.yaml として下記の内容を保存します。
apiVersion: pipecd.dev/v1beta1 kind: ECSApp spec: name: canary labels: env: example team: xyz input: serviceDefinitionFile: servicedef.yaml taskDefinitionFile: taskdef.yaml targetGroups: primary: targetGroupArn: arn:aws:elasticloadbalancing:ap-northeast-1:********:targetgroup/blue/******** containerName: web containerPort: 80 canary: targetGroupArn: arn:aws:elasticloadbalancing:ap-northeast-1:********:targetgroup/green/******** containerName: web containerPort: 80 pipeline: stages: - name: ECS_CANARY_ROLLOUT with: scale: 30 - name: ECS_TRAFFIC_ROUTING with: canary: 20 - name: ANALYSIS with: duration: 10m metrics: - strategy: THRESHOLD provider: sample-datadog interval: 1m expected: max: 10 query: | sum:aws.applicationelb.httpcode_elb_5xx{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count() / sum:aws.applicationelb.request_count{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count() - name: ECS_PRIMARY_ROLLOUT - name: ECS_TRAFFIC_ROUTING with: primary: 100 - name: ECS_CANARY_CLEAN
このファイルについて説明すると下記のような感じになります。
- kind: ECSApp として pipecd.dev/vbeta1 API にアクセス
- ECS サービスファイル・タスク定義ファイルの指定を行う
- primary, cannary として先程作成した
blue,greenのターゲットグループを指定する pipeline設定で各パイプラインのステージを指定するECS_CANARY_ROLLOUTで green ターゲットグループの ECS タスクをローリングデプロイECS_TRAFFIC_ROUTINGで green ターゲットグループに対して 20% のトラヒックを寄せるANALYSISで Datadog Metrics にクエリを投げ、閾値超過の際は FAIL するように設定ECS_PRIMARY_ROLLOUTで blue ターゲットグループの ECS タスクのローリングデプロイを実施ECS_TRAFFIC_ROUTINGで blue ターゲットグループに対して 100% のトラヒックを寄せるECS_CANARY_CLEANで green ターゲットグループの ECS タスクをクリーンアップ
※ ここでは THRESHOLD (閾値超過) の strategy を選択していますが、その他のものについては考察で述べます。
PipeCD (PipeCD Control Plane) 構築
Pipecd のコンフィギュレーション作成
Pipecd (Control Plane) のコンフィギュレーション control-plane-values.yaml を下記の通り用意します。
運用を想定すると quickstart.enabled: false として S3 や RDS 等を用いる構成が望ましいと思いますが、今回の目的ではないのでここでは quickstart.enabled: true として Pipecd を構築します。
quickstart: enabled: true config: data: | apiVersion: "pipecd.dev/v1beta1" kind: ControlPlane spec: datastore: type: MYSQL config: url: root:test@tcp(pipecd-mysql:3306) database: quickstart filestore: type: MINIO config: endpoint: http://pipecd-minio:9000 bucket: quickstart accessKeyFile: /etc/pipecd-secret/minio-access-key secretKeyFile: /etc/pipecd-secret/minio-secret-key autoCreateBucket: true projects: - id: quickstart staticAdmin: username: hello-pipecd passwordHash: "$2a$10$ye96mUqUqTnjUqgwQJbJzel/LJibRhUnmzyypACkvrTSnQpVFZ7qK" # bcrypt value of "hello-pipecd" secret: encryptionKey: data: encryption-key-just-used-for-quickstart minioAccessKey: data: quickstart-access-key minioSecretKey: data: quickstart-secret-key mysql: rootPassword: "test" database: "quickstart"
Pipecd のデプロイ
下記のように helm を使って EKS 上に Pipecd をデプロイします。
helm install pipecd oci://ghcr.io/pipe-cd/chart/pipecd --version v0.34.0 \ --namespace pipecd --create-namespace \ --values ./control-plane-values.yaml
Piped 構築
Piped はシングルバイナリとなっています。ECS API や GitHub, Datadog にアクセスするプロセスとなっています。今回の検証では EKS Cluster 上にデプロイします。
Pipecd UI にログインし piped の id, key を取得
kubernetes service に作業端末から port forwarding します。
kubectl -n pipecd port-forward svc/pipecd 8080
ブラウザで http://localhost:8080 にログインします。
- project name: quickstart
- username: hello-pipecd
- password: hello-pipecd
トップページ -> プロフィールアイコン -> Settings に遷移して Piped タブを選択し +ADD ボタンを押下。適当な名前・説明を入力し Piped ID, Key を生成したらメモする
Piped のコンフィギュレーション
piped-key-file に上記で得た Piped Key を記します。
echo '<PIPED_KEY>' > piped-key-file
コンフィギュレーションには下記のような情報を記します。
上記で得た情報等を記します。
- PipeCD UI で得た Piped ID
- PipeCD UI で得た Piped Key ファイルの指定
- 上記の手順で作成した Git レポジトリ指定
- プライベート Git レポジトリにアクセスするための SSH 鍵
- AWS リージョン情報
- AWS 機密情報のファイル指定 (後にローカルのファイルパスを指定)
- AWS 機密情報ファイル内のプロファイル名
- Datadog API, APP Key 指定
apiVersion: pipecd.dev/v1beta1 kind: Piped spec: projectID: quickstart pipedID: <上記で得た PipedID を記す> pipedKeyFile: /etc/piped-secret/piped-key apiAddress: pipecd:8080 git: sshKeyFile: /etc/piped-secret/ssh-key repositories: - repoId: <Git レポジトリ名> remote: git@github.com:<Git ユーザ/Organization 名>/<レポジトリ名>.git branch: main syncInterval: 1m cloudProviders: - name: sample-ecs type: ECS config: region: ap-northeast-1 credentialsFile: /etc/piped-secret/credentials-key profile: <AWS Profile 名> analysisProviders: - name: rf-sandbox-datadog type: DATADOG config: apiKeyFile: /etc/piped-secret/datadog-api-key applicationKeyFile: /etc/piped-secret/datadog-application-key
Piped の起動
事前に Datadog API, APP Key の内容をファイルに保存します。
echo '<Datadog API Key>' > datadog-api-key echo '<Datadog APP Key>' > datadog-application-key
下記の情報を加えて Piped を起動する。
- 上記で作成したコンフィギュレーションファイル名
piped-config-k8s-canary.yaml - 上で作成した Piped Key の内容をしるした
piped-key-file - プライベート Git レポジトリにアクセスするための SSH 秘密鍵
- AWS 機密情報を記したファイル
~/.aws/credentials - Datadog API, APP Key の内容を記したファイル指定
helm upgrade -i piped oci://ghcr.io/pipe-cd/chart/piped --version=v0.34.0 --namespace=pipecd \
--set-file config.data=./piped-config-k8s-canary.yaml \
--set-file secret.data.piped-key=./piped-key-file \
--set-file secret.data.ssh-key=/Users/foo/.ssh/pipecd \
--set-file secret.data.credentials-key=/Users/foo/.aws/credentials \
--set args.insecure=true \
--set-file secret.data.datadog-api-key=./pipecd/datadog-api-key \
--set-file secret.data.datadog-application-key=./datadog-application-key
事前のタスク定義のレジスト
事前に利用するタスク定義をレジストする必要があります。
下記の内容で taskdef-nginx.json というファイルに保存します。ECS Task Execution Role は適宜書き換える必要があります。
{ "family": "pipecd-nginx-sample", "executionRoleArn": "arn:aws:iam::********:role/ecs-taskexecution-iamrole", "containerDefinitions": [ { "name": "web", "essential": true, "image": "public.ecr.aws/nginx/nginx:1.23-alpine", "mountPoints": [], "portMappings": [ { "containerPort": 80, "hostPort": 80, "protocol": "tcp" } ] } ], "requiresCompatibilities": [ "FARGATE" ], "networkMode": "awsvpc", "memory": "512", "cpu": "256" }
下記のように awscli を用いてレジストします。
aws ecs register-task-definition --cli-input-json file://taskdef-nginx.json
動作確認
正常デプロイパターンの動作
PipeCD UI の Application の画面において下記の内容で PipeCD UI 上の Application を +ADD を押し下記の情報を入力します。
- Name に任意の名前を入力
- kind で ECS を選択
- Piped で上記の手順で登録した Piped を選択
- Cloud Provider で sample-ecs を選択
- Repository で Git レポジトリ名を選択
- Config Filename で
app.pipecd.yamlを選択
Sync ボタンを押してデプロイ開始。結果 Deployment 画面を確認すると下記の状態になります。

デプロイが進み、Primary (上記の green) への ROLLOUT (デプロイ) が完了します

Target Group green のターゲットにタスクが一つ起動し始めます
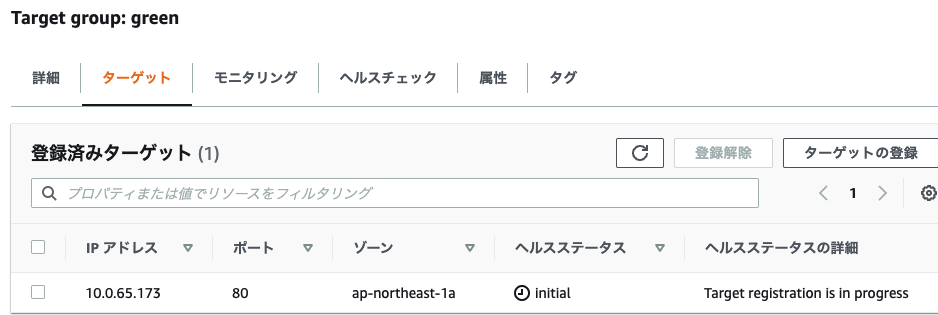
また同じタイミングで ALB リスナーを確認すると 20% のトラヒックが green に寄せられていることを確認出来ます。この状態で Datadog メトリクスを参照して閾値を超えないか確認しています (ANALYSIS)。

その後 Analysis の SUCCESS と共に Deployment が SUCCESS で完了します

その結果 green のターゲットが draining になります
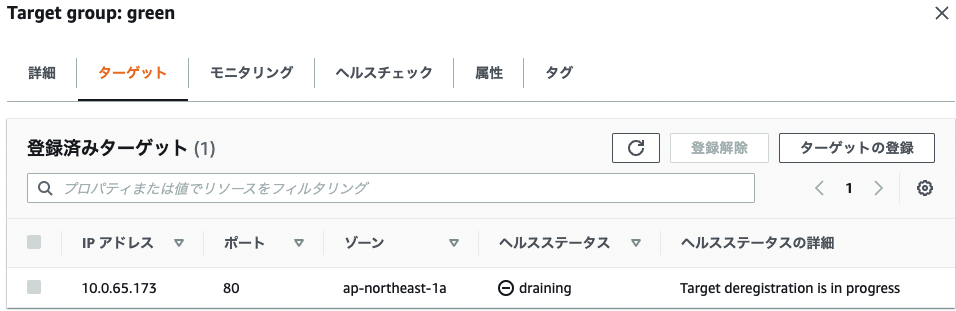
ALB Listener も blue: 100% と Canary リリースの Primary の Target Group へトラヒックが 100% 寄せられている事を確認出来ます

ANALYSIS がフェイルするパターンの動作
構築した環境で常時 0.3 以上のパーセンテージを示しているクエリに対して下記のように expected.max: 0.01 と指定してみる。
- name: ANALYSIS with: duration: 30m metrics: - strategy: THRESHOLD provider: sample-datadog interval: 10m expected: max: 0.01 query: | sum:aws.applicationelb.httpcode_elb_5xx{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count() / sum:aws.applicationelb.request_count{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count()
結果としてはパイプラインの ANALYSIS ステージで想定した通り Fail し、結果 ROLLBACK されました。これも期待通りの動作です。
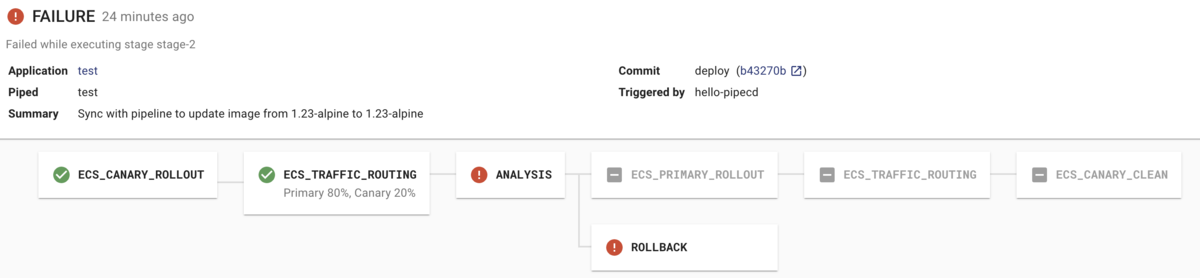
考察
動作確認したとおり、カナリーリリース・Datadog Analysis・THRESHOLDS 戦略を用いて動作確認が出来て、
- (1) デプロイ開始
- (2) Canary 環境へデプロイ
- (3) 部分的にトラヒックを Canary に寄せる
- (3) Datadog Metrics を解析しつつ問題なければ Primary 環境へデプロイ
- (4) Primary に100%のトラヒックを寄せる
- (5) Canary 環境をクリーンアップ
という流れで、カナリーリリースとプログレッシブデリバリーが実践出来ました。これは今の READYFOR の ECS 環境には無い機能となっていいて今後の期待が膨らみます。
Datadog Analysis Provider 利用時の注意点
ただいくつか課題があります。そのうちの一つが Datadog と連携する事に関するものです。
通常であればアプリケーションをデプロイし、ALB のエラー率等を計測しそれを Analysis Provider で指定することになります。その場合 AWS Intergration の機能で Cloudwatch Metrics -> Datadog Metrics とメトリクス情報を送信する必要がありますが、
- AWS -> Datadog 連携でメトリクス反映に数分程度の遅延がある
- ALB メトリクスのプロットのインターバルが1分である
という問題が浮上します。これによって下記のような Analysis Provider の設定を app.piped.yaml に施すと
- name: ANALYSIS with: duration: 10m metrics: - strategy: THRESHOLD provider: sample-datadog interval: 1m expected: max: 10 query: | sum:aws.applicationelb.httpcode_elb_5xx{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count() / sum:aws.applicationelb.request_count{env:prd,hostname:sample-lb-********.ap-northeast-1.elb.amazonaws.com}.as_count()
- Datadog Metrics への確認インターバルが
1mなので AWS Integration 経由の Datadog Metrics の遅延の長さより短いせいで no data point to compare というエラーが発生する - その結果、Analysis Provider による解析がスルーされる
- 結果、一度も計測されずにデプロイが SUCCESS してしまう
という状況が発生します。
このことから
- duration: 30m
- interval: 10m
程度の設定をすればいいのですが、この結果として一回の解析で数回程度のデータしか解析されない事になります。
この事や、下図から下記の条件を満たす必要があると判ります。
metrics.interval>Cloudwatch -> Datadog Metrics 転送遅延長
このことは秒単位で exporter からのデータを Scrape する Prometheus では問題になりません。実際 PipeCD は Prometheus を一番のターゲットにして開発されています。(コンフィギュレーションの scrape_interval (default: 1s) に相当する) よって、Datadog を Analysis Provider に利用する際には下記の幾つかの方法を検討する必要があります。
(1) ALB のメトリクスを収集し Datadog カスタムメトリクスへプロットするプロセスを ECS などで稼働する構成で問題回避できるか
タイトルの通り、ALB のメトリクスを収集して Datadog カスタムメトリクスへデータを送信するプロセスを開発し ECS クラスタ上で稼働させる構成を組み、そのカスタムメトリクスを指し示す Datadog Analysis Provider の設定記述をすることで、上記の問題を解決出来ると想定していましたが、AWS 様のサポートより情報を得て、ALB メトリクスは 60秒間隔 で変えることは出来ず、また API 経由でメトリクスを取得してもこのことは変わらない、ということでこの構成を組んだとしても上記の Datadog Analysis Provider 利用時の問題を回避することが出来ないとわかりました。
(2) Prometheus & Cloudwatch Exporter を稼働する構成で問題回避できるか
Cloudwatch Exporter (https://github.com/prometheus/cloudwatch_exporter) を利用して Cloudwatch Metrics のデータを取得し Prometheus Exporter として Prometheus Server からのポーリングを待ち受ける構成を考えました。下記は公式ドキュメントからの引用です。
--- region: eu-west-1 metrics: - aws_namespace: AWS/ELB aws_metric_name: RequestCount aws_dimensions: [AvailabilityZone, LoadBalancerName] aws_tag_select: tag_selections: Monitoring: ["enabled"] resource_type_selection: "elasticloadbalancing:loadbalancer" resource_id_dimension: LoadBalancerName aws_statistics: [Sum]
この場合の構成は下記のようになります。
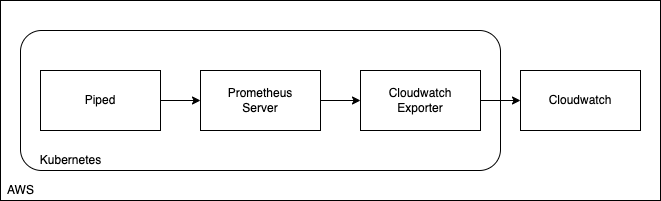
ただこの構成の場合にも ALB メトリクスは 60秒間隔 なので Cloudwatch Metrics 上でもこのことは変わりません。よって導入メリットとしては
- Cloudwatch -> Datadog 間のメトリクス送信遅延が無い点では有利
という1点だけ、ということになります。
(3) Cloudfront (リアルタイムログ) -> Kinesis Data Stream -> Lambda (Datadog Custom Metrics Send) の構成で回避出来るか
下記の構成であれば秒単位でメトリクスデータが扱えそうです。
CloudFront (リアルタイムログ) → Kinesis Data Streams → Lambda 関数 (PutMetricData API の実行)
ただしこの構成の場合、ターゲットの生成する 5XX コードか ALB の生成する 5XX コードかを見分けることは出来ない様です。また環境構築・調査検証・開発、と作業工数は高くなりそうです。
その他の Analysis のパイプライン戦略について
また検証では THRESHOLDS という閾値設定型の戦略を取りましたが、他にも幾つかの戦略が PipeCD には存在します。下記がそれらです。
(1) PREVIOUS : メトリックを最後に成功したデプロイメントと比較する方法
下記は例で前回 (最後) のデプロイメントのメトリクスクエリ計測結果と比較して、前回よりも偏差が高い場合、Fail する、というものになっています。
apiVersion: pipecd.dev/v1beta1 kind: KubernetesApp spec: pipeline: stages: - name: ANALYSIS with: duration: 30m metrics: - strategy: PREVIOUS provider: my-prometheus deviation: HIGH interval: 5m query: | sum (rate(http_requests_total{status=~"5.*"}[5m])) / sum (rate(http_requests_total[5m]))
(2) CANARY_BASELINE : Canary バリアントと Baseline バリアントの間でメトリックを比較する方法
下記は例で Canary, Baseline とでメトリクスを比較しつつ、最終的に deviantion: HIGH という条件で Fail します。
apiVersion: pipecd.dev/v1beta1 kind: KubernetesApp spec: pipeline: stages: - name: ANALYSIS with: duration: 30m metrics: - strategy: CANARY_BASELINE provider: my-prometheus deviation: HIGH interval: 5m query: | sum (rate(http_requests_total{job="foo-{{ .Variant.Name }}", status=~"5.*"}[5m])) / sum (rate(http_requests_total{job="foo-{{ .Variant.Name }}"}[5m]))
(3) CANARY_PRIMARY (非推奨) : Canary バリアントとPrimary バリアントの間でメトリックを比較する方法
非推奨の戦略。何らかの理由でベースラインバリアントを提供できない場合は、Canary と Primary を比較することができる。
所感
インフラの構成自体は非常にシンプルでまた Kubernetes リソースのメンテナンス・移行等を想定したとしても、サービスを支えている ECS 環境には影響が出ないので、比較的その様な作業もし易い様に思えました。
ただ、下記のことを運用前に検証・開発する必要がある認識です。
S3, RDS 利用の構成検証
検証時Pipecd (Controll Plain) 側の構成は Quickstart 的なコンフィギュレーションや構成を利用したので、実際に運用する際には Minio -> S3, MySQL -> RDS といったマネージドサービスを利用する構成を設計しなくてはいけません。これは EKS 上のコンテナをステートレスに扱う事に繋がります。
Datadog Analysis Provider 利用時の問題解消のための検証・開発
また、上記の考察の項で記した Datadog Analysis Provider 利用時の Cloudwatch Metrics -> Datadog Metrics の送信遅延問題に対応するため、「Cloudfront -> Kinesis Data Stream -> Lambda -> Datadog 構成の検証・開発」もしくは「EKS 上での Prometheus Server と Cloudwatch Exporter の構築」のいずれかが必要になってきます。
Event Watcher 動作問題
また PipeCD Event Watcher によるアプリケーションの Auto Sync 設定も検証したのですが、今の所自分の環境では動作確認出来まていません。
アプリケーションレポジトリに .pipe/event-watcher-ecs.yaml として下記を保存。(パラメータについては公式ドキュメントを参照のこと)
apiVersion: pipecd.dev/v1beta1 kind: EventWatcher spec: events: - name: pipecd-sandbox-canary-image-update replacements: - file: taskdef.yaml yamlField: $.containerDefinitions[0].image
pipectl コマンドを作業端末にインストール。
$ curl -Lo ~/.bin/pipectl https://github.com/pipe-cd/pipecd/releases/download/v0.34.2/pipectl_v0.34.2_darwin_amd64
pipectl を使って Event をレジスト (Web UI では今のところ出来ない)
pipectl event register --address=http://localhost:8080 \ --api-key-file=/Users/foo/rf/infra/pipecd/api-key-file \ --name=pipecd-sandbox-canary-image-update \ --data=public.ecr.aws/nginx/nginx:1.23-alpine-perl
結果、下記のエラーが発生。
Error: failed to initialize client: context deadline exceeded
原因はまだ判っていません。API Address の指定が kubectl を使った Port Forwarding によって待ち受けているアドレスなのが問題か、他の原因があるか今のところ不明。もし前者が原因であればいずれは ALB Ingress Controller による PipeCD Control Plain の Ingress 対応はしなくてはいけなさそうです。